Abstract
Constructing photo-realistic Free-Viewpoint Videos (FVVs) of dynamic scenes from multi-view videos remains a challenging endeavor. Despite the remarkable advancements achieved by current neural rendering techniques, these methods generally require complete video sequences for offline training and are not capable of real-time rendering.
To address these constraints, we introduce 3DGStream, a method designed for efficient FVV streaming of real-world dynamic scenes. Our method achieves fast on-the-fly per-frame reconstruction within 12 seconds and real-time rendering at 200 FPS. Specifically, we utilize 3D Gaussians (3DGs) to represent the scene. Instead of the naïve approach of directly optimizing 3DGs per-frame, we employ a compact Neural Transformation Cache (NTC) to model the translations and rotations of 3DGs, markedly reducing the training time and storage required for each FVV frame. Furthermore, we propose an adaptive 3DG addition strategy to handle emerging objects in dynamic scenes.
Experiments demonstrate that 3DGStream achieves competitive performance in terms of rendering speed, image quality, training time, and model storage when compared with state-of-the-art methods.
Method

Given a set of multi-view video streams, 3DGStream aims to construct high-quality FVV stream of the captured dynamic scene on-the-fly. Initially, we optimize a set of 3DGs to represent the scene at timestep 0. For each subsequent timestep i, we use the 3DGs from timestep i-1 as an initialization and then engage in a two-stage training process:
Stage 1: We train the Neural Transformation Cache (NTC) to model the translations and rotations of 3DGs. After training, the NTC transforms the 3DGs, preparing them for the next timestep and the next stage in the current timestep.
Stage 2: We spawn frame-specific additional 3DGs at potential locations and optimize them along with periodic splitting and pruning.
After the two-stage process concludes, both transformed and additional 3DGs are used to render at the current timestep i, with only the transformed ones carried into the next timestep.
Evaluations
Comprehensive Comparison with Previous Methods

Comparison on the flame steak scene of the N3DV dataset. The training time, requisite storage, and PSNR are computed as averages over the whole video. Our method stands out by the ability of fast online training and real-time rendering, standing competitive in both model storage and image quality.
Fast Training & Real-time Rendering
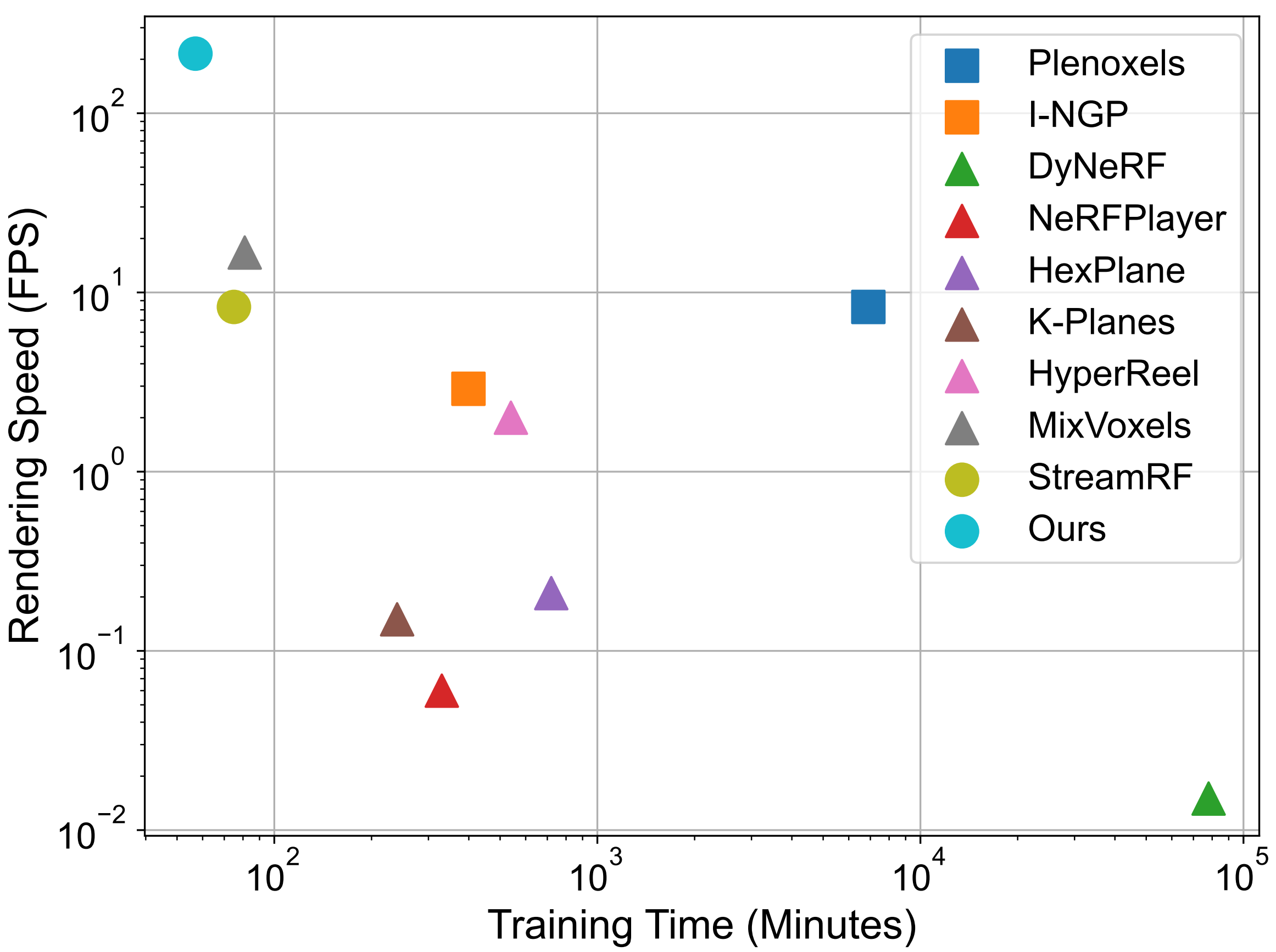
Comparison of our method with other methods on the N3DV dataset. ◼ denotes training from scratch per frame, ▲ represents offline training on complete video sequences, and ● signifies online training on video streams. While achieving online training , our method reaches state-of-the-art performance in both rendering speed and overall training time.
Photo-Realistic Visual Quality

Visual comparisons on the discussion scene of the Meet Room dataset and the sear steak scene of the N3DV dataset. While our approach primarily aims to enhance the efficiency of online FVV construction, it still achieves competitive visual quality.
Modeling Emerging Objects

Ablation study on our proposed Adaptive 3DG Adition strategy, highlighting its ability to reconstruct the objects not present in the initial frame, such as coffee in a pot, a dog's tongue, and flames.
BibTeX
@InProceedings{sun20243dgstream,
author = {Sun, Jiakai and Jiao, Han and Li, Guangyuan and Zhang, Zhanjie and Zhao, Lei and Xing, Wei},
title = {3DGStream: On-the-Fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
pages = {20675-20685}
}